Emulator Build-Up¶
Building the emulator requires different stages:
generating the training points
training the Gaussian Processes
The inputs are generated using Latin Hypercube sampling and these are scaled using the priors module below. One can specify a prior using the dictionary format as follows:
{'distribution': 'uniform', 'specs': [0.06, 0.34]}
where specs are the specificifications for the distribution. In the example above, 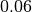 is the minimum and the maximum is
is the minimum and the maximum is 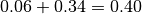 . Note that we are using
. Note that we are using scipy.stats and hence the above convention. The GP models are trained in parallel (number of cores available on your computer) and are stored.